




This week, Okta shared a postmortem for its recent incident. Much has been said by me (and others) about the way Okta handled the incident. Note that these previous statements were made in a personal capacity and I was not representing SCYTHE at the time. Not only are my personal tweets personal, but I wasn’t yet employed with SCYTHE at that time.
Wow has a lot changed in the last month. Not only do I have a new job, but Okta has also concluded its investigation and postmortem. There’s a lot in the postmortem, but I want to focus on the specific portion where Okta notes that it will be managing the devices of third parties that use its customer support tools. I wrote a bit about that already on Twitter, but want to expand those thoughts a bit in a longer form post.
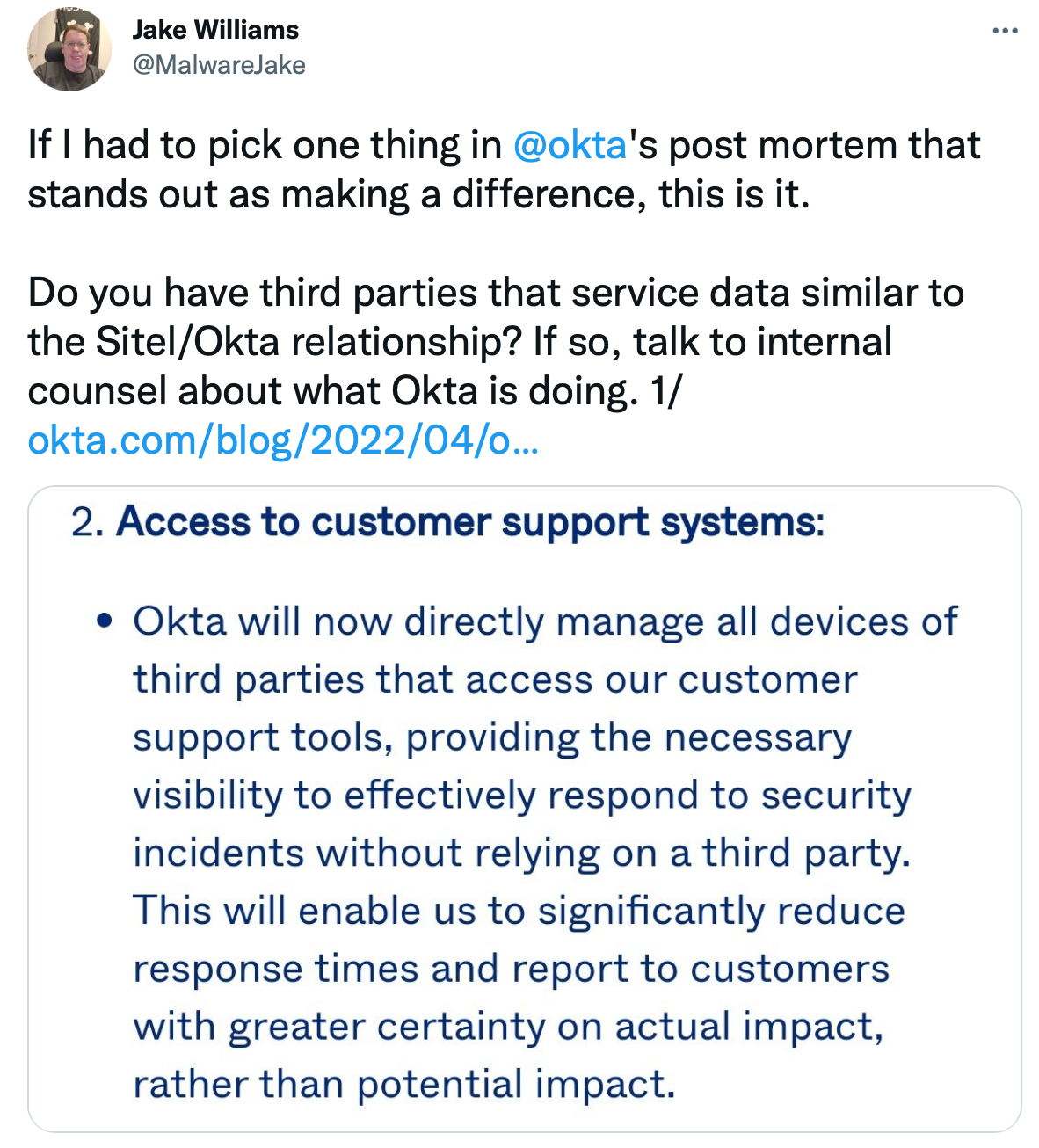
As I noted in the thread, managing the devices of another organization may lead to new security and compliance challenges. One of the first questions I’d have about a decision like this is how the RACI chart breaks down for “management” of the devices, while noting that it might be different for different types of devices (e.g. phone vs laptop vs desktop workstation). RACI notwithstanding, Okta’s statement that this will allow it to reduce response times and more easily investigate incidents is almost certainly correct.
Any time analysts have access to source data, that’s almost certainly better for an investigation than obtaining summary data. But as we’ve seen time after time, most analysts misunderstand what their security controls will block or detect. When neither occurs and analysts must begin analyzing logs and other telemetry to reconstruct an event, this lack of certainty is magnified significantly. While I applaud Okta for increasing telemetry and (hopefully) decreasing investigation times, I want to heavily recommend that others looking to emulate Okta’s goals don’t stop with what’s in the postmortem alone.
Properly investigating incidents requires really understanding your controls and the telemetry created for a given action. During incident response operations we regularly engage in ad hoc Purple Team exercises to understand whether our hypothesis about action to telemetry mappings are in fact correct. We don’t need this for common Windows or Linux OS logs (as long as we aren’t dealing with one-off configurations), but for third party applications with few installations, this is almost always necessary. For custom applications, if you’re relying on action to telemetry mappings, anything less than validation is borderline negligent.
It should go without saying that the proper time for a Purple Team exercise is not during an incident. In fact, doing so before an incident makes you more likely to detect an intrusion in the first place. In reality, most organizations simply lack the resources to conduct Purple Team exercises in the scope and quantity needed to stay on top of understanding their controls. I won’t go into all the ins and outs of conducting a Purple Team exercise - our own Jorge Orchilles has done a fantastic job of that with the Purple Team Exercise Framework.
Coming back to Okta and managing the devices of third parties, this certainly wouldn’t be the first time I’ve seen this. In almost every case, this eventually transitions to “the third party is responsible for patch management and configuration, but we manage the EDR” (or at least have access to the telemetry). The problem here is that the devil (as always) is in the details. A simple OS configuration change can dramatically change the telemetry an organization receives from an EDR (or other security control). But if you don’t know that, you’re making bad decisions based on faulty data. And unless you’ve taken over complete management of third-party devices, there will be deviations from your baseline configurations.
This is where control validation rules the day - and it’s something we need more of. Ideally, every time you change a configuration of a device (whether to the OS, applications, or security controls), you should revalidate your action to telemetry mappings. Of course very few organizations do this, but I believe that’s because most organizations simply lack the throughput to make it possible. For that matter, most organizations lack the in-house expertise to run a single point-in-time Purple Team exercise correctly. Performing control validation at scale for these organizations is an unrealistic pipe dream.
These are some of the many reasons I’m excited to be at SCYTHE. I’ve seen first-hand that most organizations can’t run Purple Team exercises at all, let alone at scale. I’ve observed how misunderstanding your action to telemetry mappings leads to missed detection opportunities and increased dwell times. Tragically, I’ve witnessed (extremely confident) investigators and analysts make materially false statements about what their telemetry is telling them. Even worse is when these statements are forwarded to regulators (eek!).
Whether or not you’re looking at taking over management and monitoring of third party devices, you should absolutely be considering how you’ll scale Purple Team exercises and control validation. It’s almost certainly something we’ll see more demand for from regulators. And this makes sense. Control validation is the only way to go from “it should” to “it does - let me show you how I know.”
Latest Posts

MuddyWater Displaying New Tactics and Intriguing Malware
March 20,2026

Key Takeaways from UniCon 2025 – Fall Edition
September 28,2025
Related Articles

.png?width=352&name=60672df8c488714d85f1aafe_Emulation%20(2).png)